

Over the last six months, some of the biggest infrastructure providers on the internet, including AWS, Cloudflare, and GitHub, have all had some pretty massive and high-impact outages. GitHub especially has been struggling with uptime, so much so that they have their CTO writing apology posts and long-time maintainers packing their bags. For a long time, the handful of companies running things were quietly doing their jobs without much fuss, and the abstraction just worked. But the infrastructure which allowed that and which was supposed to be the boring part has been slowly getting worse and as it turns out it's not working all so well anymore.
Instead of one big dramatic crash it's been more the case of a slow, grinding buildup of incidents that have turned "is it just me or is GitHub down?" into a weekly question. The old five nines of 99.999% availability, meaning 5 minutes of downtime per year, was always aspirational for a platform of GitHub's scope, but recently we're watching that uptime slip more and more, all the way from 99.9% toward 89.9%.

Two incidents in one week
Taking a look at the first incident on April 23 GitHub's merge queue quietly started reverting code on the main branche. A simple 29-line PR went through review, hit the queue, and what landed on main was a single commit that deleted over a thousand lines of unrelated, already-shipped code. Every merge that followed just piled onto that broken history.
Then, a few days later, just when you thought it surely couldn't get worse than this, you guessed it. It got worse. The security firm Wiz dropped a nasty vulnerability, CVE-2026-3854, that basically gave an unauthenticated path to remote code execution from a single git push. A semicolon in the wrong place let researchers escape the sandbox and land on a shared node serving millions of repos, thereby gaining access to cross-tenant data.
Either of these would make for a terrible week, but both happening within seven days, on top of an already sliding reliability record, reflects really badly on the reputation of the platform as a whole.
The community's response
Of course, the general reaction was pretty sharp. People started asking the obvious question: at what point would customers move, and where would they move to? GitHub's response leaned hard into percentages, pointing out that the merge bug only affected "roughly 0.07%" of PRs. But if you were one of the teams that spent the afternoon force-rebuilding your repository's history, you probably didn't find any conciliation in that number.
And on top of that, you have developers like Mitchell Hashimoto who is the man behind Ghostty, a fast-growing open-source terminal emulator (which also happens to be my terminal of choice) writing earlier this week that he was moving the project completely off the platform because the platform just isn't as reliable as it used to be. Armin Ronacher who is the creator of Flask as well as the founder of Sentry, and one of the most respected long-time voices in the Python and open-source community published a piece titled "Before GitHub" the same week, reminding developers that there was an open-source ecosystem before the centralized platform, and there will be one after it as well. This all leads to the point that when senior practitioners with no axe to grind start visibly recalculating their reliance on a tool, the platform has a real problem.
The AI elephant in the room
So what's actually causing this? If you read GitHub's own write-up, it's quite revealing. Rather honestly they admit that they had planned to 10x their capacity starting in late 2025, but by February 2026, they had to bump that target to 30x.
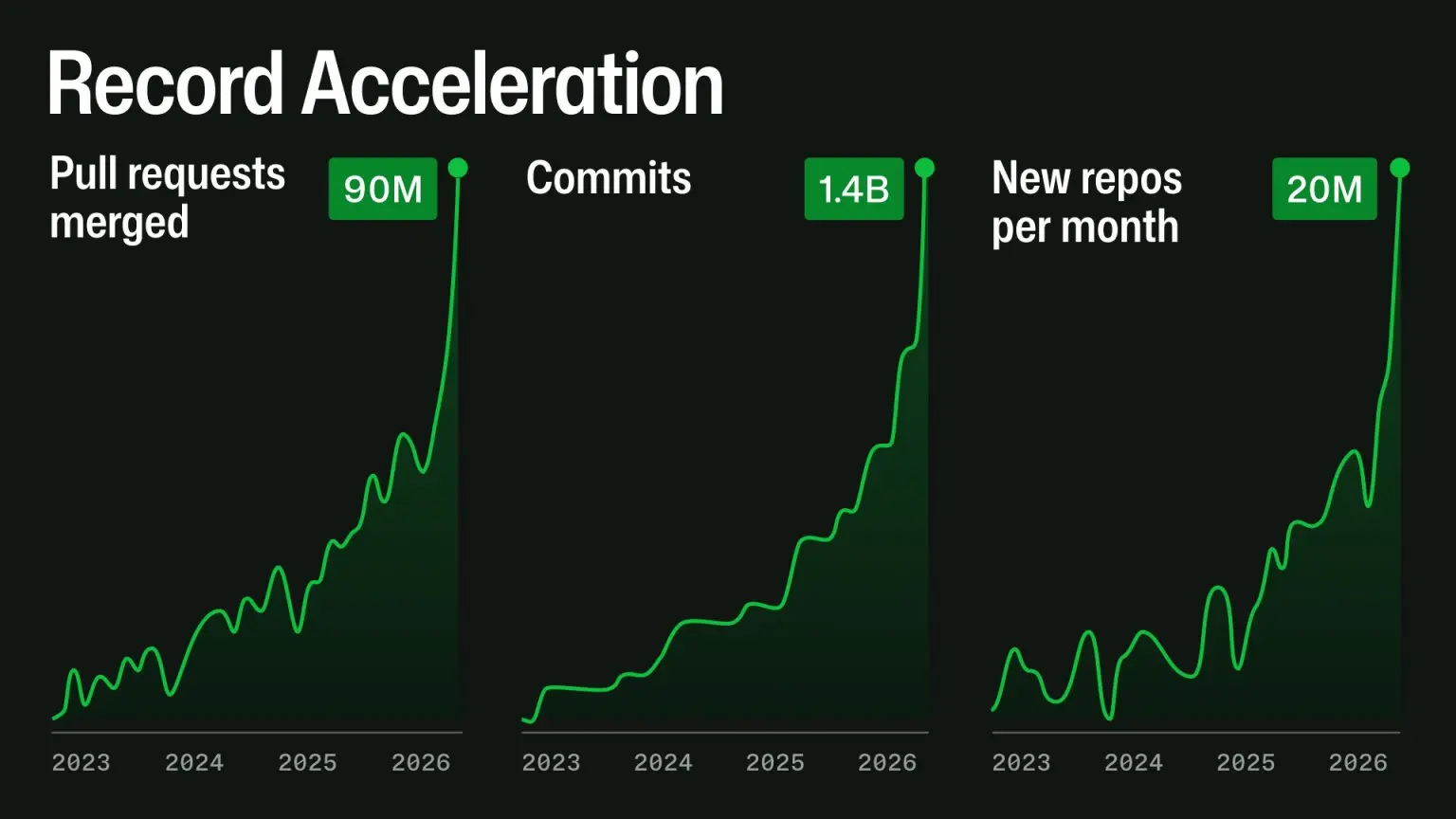
The culprit is what they're calling "agentic development workflows." Basically, AI coding loops like Claude Code and Cursor are flooding the system. A normal human developer might open a few PRs a day but an AI agent can hammer out dozens per hour, per repo. Each one hits CI, branch protections, the API, the search index, and webhooks. The graphs they published tell you everything you need to know: pull requests merged peaking near 90M per month, commits at 1.4B, and new repos at 20M. Almost no platform was built for this kind of traffic.
Where does it go from here?
There are quite a few plausible ways this plays out over the coming years, but they generally boil down to:
- GitHub slowly recovers: They isolate services, rewrite the hot paths, and build smarter APIs. The engineering problem is hard, but well-understood. This is probably the most likely long-term outcome, though it might take 12–18 months of growing pains to get there.
- The ecosystem fragments: High-profile open-source projects might mirror to, or fully migrate to, platforms like Codeberg or self-hosted instances. The community spreads out, and discovery gets genuinely messier than it is today.
- The AI load flattens: We might start seeing aggressive API rate limiting on agents, or these workflows might shift to private forks that only push on demand. The math of scaling 30x every six months just isn't sustainable without changing how the inputs work.
That third option is the one I'd bet on. The reason agent traffic exploded in the first place is that, for the better part of two years, the real cost of running an AI loop has been hidden from the developer and subsidized by providers trying to draw people in. Flat-rate Copilot seats, generous "premium request" allotments, and aggressive promotional pricing all combined make a pretty sweet deal. Sure why not spin up a coding agent and let it churn. But it seems that phase is now ending as Copilot has just moved to usage-based billing, with per-model multipliers that align cost much more closely with what each request actually consumes on the backend. Once that economic reality lands inside engineering orgs, a lot of "let the agent grind on it overnight" workflows start to look very different on the invoice and so does the volume of pushes, PRs, and CI runs they generate against GitHub.
One other interesting takeaway is that Git itself has almost nothing to do with the recent failures. The core tech is fine — it's just the centralized social and CI/CD layer built on top of it that is buckling under its own weight.
Wrapping up
This can all sound pretty doom and gloom, but rest assured: if you're someone who writes code for a living, there's no need to panic and migrate tomorrow. Think of this more as a good moment to do some boring, practical housekeeping:
- Treat GitHub Actions like any other dependency: If your release pipeline breaks when Actions goes down, that's a single point of failure on your business. Build a local fallback path so you can manually push a release from a clean checkout if needed. Test it once a quarter.
- Mirror your critical stuff: Code, releases, issue exports, and your wikis. The cost is small and the optionality is huge. Setting up a remote is literally one line in Git.
- Read the incident reports with charity: The folks at GitHub are dealing with insane distributed-systems load conditions that basically didn't exist 18 months ago.
At the end of the day, it's a trade-off. You give these centralized providers your data, your workflow, and your trust. They give you reliability and performance. When one side drops the ball, it's totally fair to start looking at your options.



































