

AI-referred traffic to websites grew 527% between January and May 2025. ChatGPT, Claude, Perplexity, and Gemini are sending visitors to businesses they understand and recommend. The rest get ignored.
Traditional SEO optimizes for Google's crawler. It does not address how large language models read, interpret, and cite your website. Your pages rank on Google, but when someone asks ChatGPT "who builds custom booking platforms in Croatia," the answer does not include you. The LLM never found the right information, or it found your HTML and burned through tokens trying to parse navigation menus and footer scripts.
We spent the past months building a complete AI discovery infrastructure on workspace.hr. Eight components, all open standards, all running in production. AI assistants now find us, understand what we do, describe us correctly, and recommend us for the right projects. They also know when not to recommend us, filtering out leads before they waste both sides' time.
This post covers the full stack. Every component, why it exists, and how to implement it.
Why AI assistants skip your website
The HTML problem
When a language model reads your website, it downloads the same HTML your browser renders. Header, navigation, cookie banners, SVGs, inline styles, footer links, tracking scripts. All of it. A typical page produces 15,000-30,000 tokens of HTML. The actual content accounts for 2,000-4,000 tokens buried somewhere in the middle.
LLMs have context windows. Every token spent on your navigation menu is a token not spent understanding your value proposition. When a model processes 50 websites to answer a question, yours gets the same token budget as everyone else. If 80% of your tokens are boilerplate, you lose.
No rulebook for AI discovery
Google has schema.org markup, meta descriptions, and sitemaps. Twenty years of standards telling crawlers where to look and what to extract. AI agents have no equivalent. No single specification. No unified protocol. No industry-wide agreement on how a language model should discover, read, or cite your website.
What exists today is a loose collection of early proposals. llms.txt is a community-driven draft. Content Signals launched months ago. Cloudflare published an Agent Skills Discovery RFC at version 0.2.0. These are starting points, not finished standards. Nobody owns this space. No governing body enforces compliance. There is no Google Search Console for AI visibility.
This is the reality: you are building for a system with no fixed rules. Without any structured signals, an LLM works with whatever text it scraped. It fills gaps with assumptions. It mispositions your services. It recommends you for work you do not take. Or it recommends a competitor because their content was easier to parse.
The discovery gap
Traditional web infrastructure gives crawlers a robots.txt for access rules and a sitemap.xml for page discovery. AI agents need more, and nobody has defined what "more" looks like yet. There is no W3C specification for AI discovery. No RFC governing how language models should index websites. The ecosystem is fragmented: different AI companies read different signals, support different formats, and change their behavior between model versions.
AI agents need to know your services, your ideal clients, your tech stack, your case studies, and how you want to be described. They need this in a format optimized for language model consumption, not for browser rendering. But which format? There is no single answer. So we built for all of them.
Less than 0.1% of websites have implemented any form of AI-specific discovery infrastructure. Gartner projected 25% of organic search traffic would shift to AI chatbots by 2026. We are already there. AI-powered search tools captured 12-15% of global search market share by end of 2025. Perplexity alone processes 780 million queries per month.
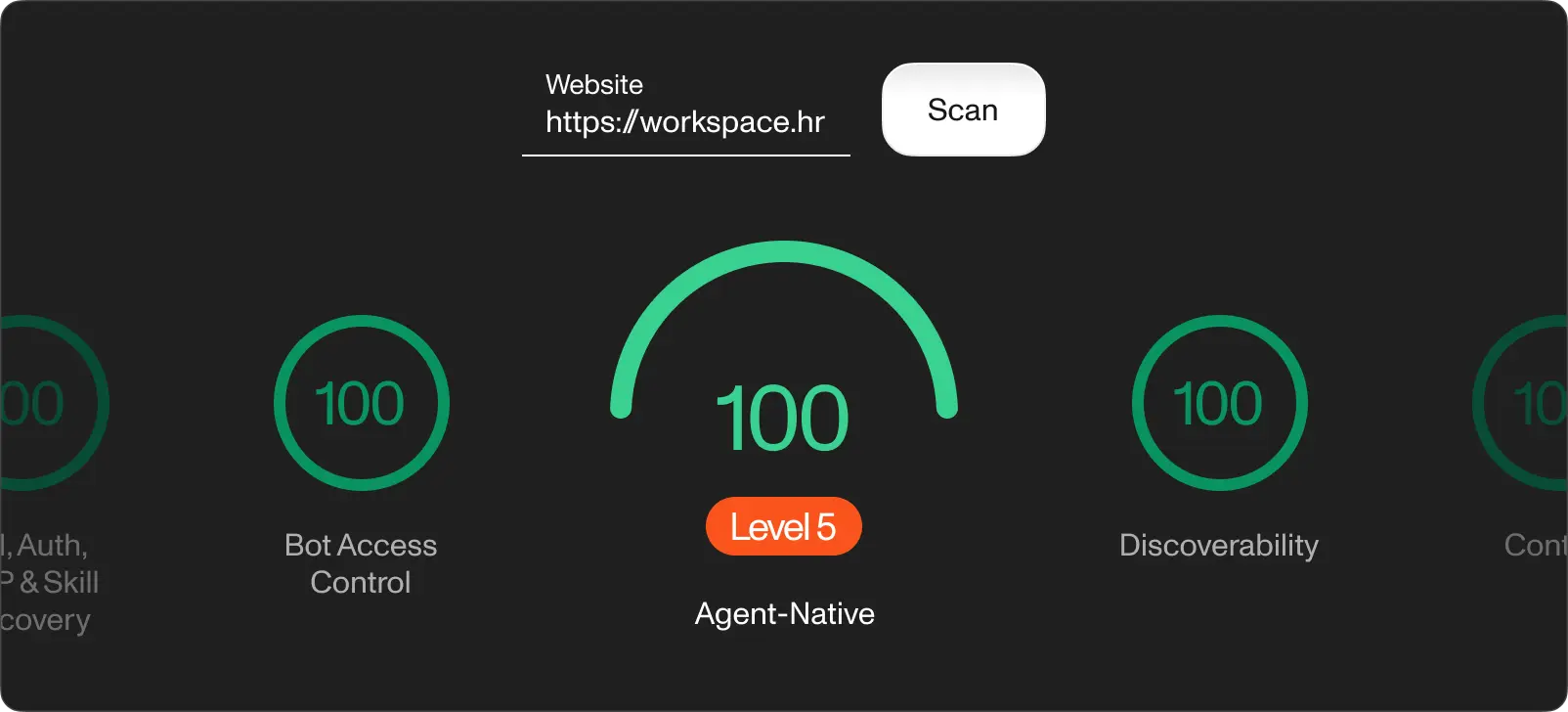
Cloudflare released a free scanner called Is It Agent Ready? in April 2026. It works like Lighthouse for AI readiness: paste your URL, get a score from 0 to 100, and see which checks pass or fail. Most websites score in the Basic tier. We ran workspace.hr through it after deploying our full stack. Try it on your own site. The gap between your score and ours is a rough measure of the work ahead.
The 8-component AI infrastructure stack
No single standard covers everything. We assembled eight components from different sources: community proposals, early-stage RFCs, Cloudflare experiments, and patterns we developed ourselves. Some of these will become official standards. Some will get replaced. All of them work right now. Here is what we implemented and why.
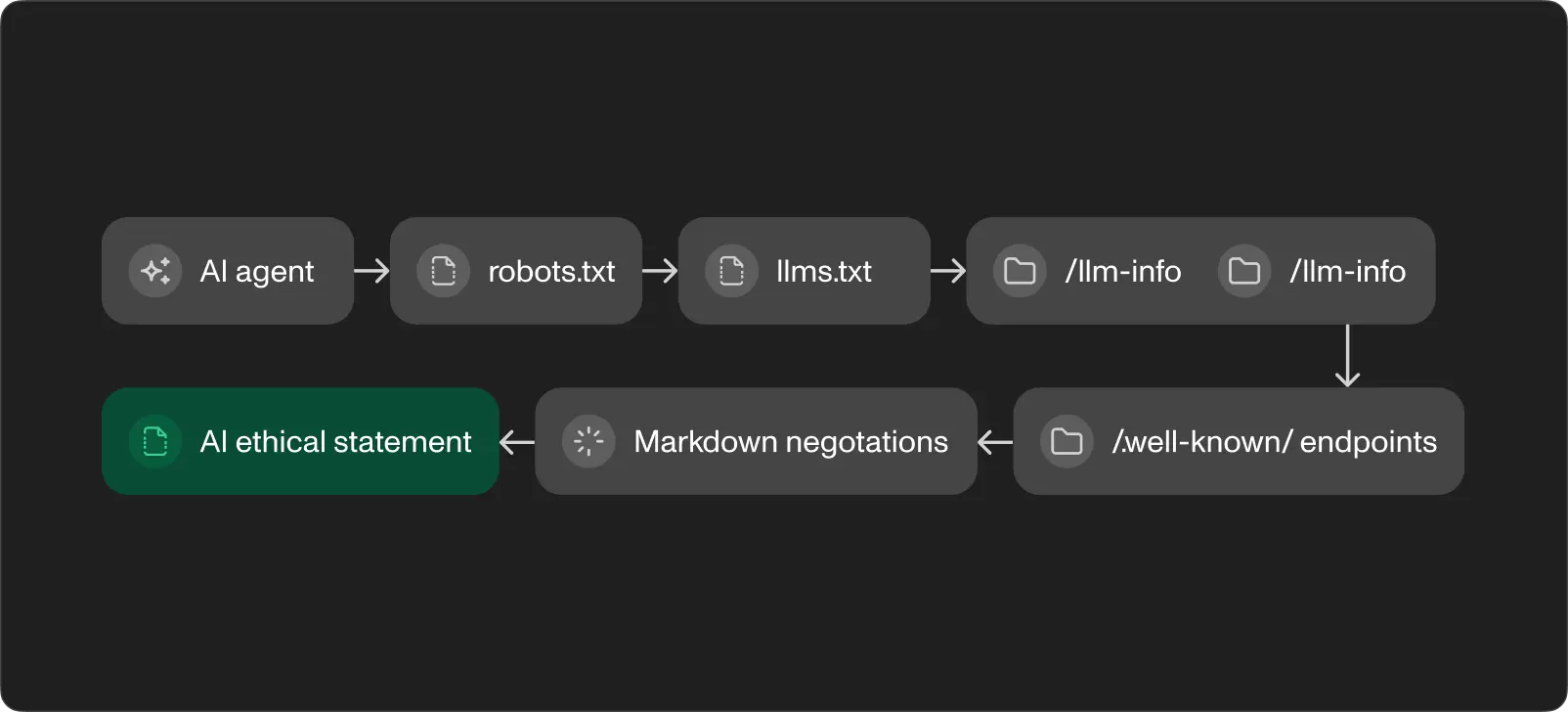
robots.txt with Content Signals. The first file any crawler reads. We added Content Signal directives declaring our AI usage policies: search=yes, ai-train=yes, ai-input=yes. These tell AI crawlers they are welcome to index, train on, and use our content as input for responses. You control each permission independently.
llms.txt root index. A plaintext Markdown file at /llms.txt following the llmstxt.org standard. It gives AI agents a compact map of your site: who you are, what you do, where to find detailed information. A sitemap designed for language models instead of search crawlers. Under 100 lines, linking to everything relevant.
llm-info.json structured payload. A JSON-LD endpoint at /llm-info.json containing machine-readable data about your organization. Services, tech stack, case studies, competitive advantages, and the 2 fields worth the most attention: instructionsForAI and idealFit/nonFit. The instructions tell AI assistants exactly how to describe your company. The fit profiles filter out unqualified leads before they reach your inbox.
llm-info human-readable page. A dedicated page at /llm-info with the same information in Markdown, optimized for both AI parsing and human reading. We publish ours in English and Croatian. This page is indexed by search engines and serves as a landing page for anyone curious about what AI knows about your business.
AI ethical statement. A public page declaring your AI usage principles, aligned with the EU AI Act and GDPR. It covers human oversight, data governance, transparency, and accountability. This builds trust with B2B clients who increasingly ask about AI policies in RFPs and procurement processes.
Agent Skills Discovery. Following Cloudflare's RFC v0.2.0, we publish a skills index at /.well-known/agent-skills/index.json. Each skill teaches AI agents how to interact with your site. One skill explains markdown content negotiation. Another points to AI info endpoints. The system is self-documenting: agents learn what your site offers and how to use it.
Markdown content negotiation. A middleware layer detecting the Accept: text/markdown header, converting HTML pages to clean Markdown on the fly. An AI agent requesting any page with this header gets structured Markdown instead of bloated HTML. The response includes an x-markdown-tokens header with the approximate token count, helping the agent plan its context budget. Token savings: 50-70% compared to raw HTML.
Discovery endpoints. Standard .well-known endpoints for API catalog (RFC 9727), OAuth protected resource metadata (RFC 9728), and OpenID Connect discovery. Every HTTP response from our site includes Link headers advertising all AI endpoints. An agent visiting any page finds the entire infrastructure through response headers alone.
How these components connect
The flow is sequential. An AI agent hits robots.txt and learns it is welcome. It follows the link to llms.txt and gets the site map. It reads llm-info.json for structured data and instructions. If it needs page content, it sends Accept: text/markdown and gets clean, token-efficient Markdown. The agent skills index tells it what else the site offers. Discovery headers on every response reinforce the path.
Each layer reduces ambiguity. By the time the agent has your instructionsForAI, it knows what you do, who you serve, how to describe you, and when not to recommend you. This precision turns a generic AI mention into a qualified referral.
Implementation details worth getting right
Use JSON-LD (application/ld+json) for the structured payload, not plain JSON. Schema.org context gives AI agents a shared vocabulary. Set CORS headers (Access-Control-Allow-Origin: *) on all AI endpoints so cross-origin fetching works without friction. Cache aggressively: Cache-Control: public, max-age=3600 minimum. AI crawlers hit these endpoints repeatedly, and stale data is better than failed requests.
The instructionsForAI array is the highest-value field in the entire stack. Write it like you are briefing a new team member on the first day. Be specific about what your company does, who it is for, and what it does not do. The idealFit and nonFit fields work as filters. AI agents use them to match your business against the user's query. A well-written nonFit section saves more time than a polished sales pitch because it prevents conversations going nowhere.
How we use this at Workspace
We deployed this infrastructure on workspace.hr and tested it across ChatGPT, Claude, Perplexity, and Gemini. The results show up in how these tools describe and recommend us.
Ask ChatGPT or Perplexity about custom software teams in Split, Croatia, or about booking platform development. Workspace appears in the answers. The descriptions are accurate: they mention our end-to-end capability, our work in the charter and maritime industry, and our AI services line. They link to workspace.hr and to our contact page. This did not happen before we implemented the infrastructure.
The idealFit filtering works both ways. We defined our ideal clients as SMEs where software directly supports operations, founders close to their processes, and charter and marine businesses. The nonFit field flags tiny one-off tasks and large enterprise procurement. AI assistants now steer away from recommending us for work we do not take, which means fewer dead-end conversations.
We applied the same approach to Serwizz, our CMMS product. When a maintenance manager asks an AI assistant for an intuitive CMMS with easy adoption and real people behind it, the structured data points Serwizz as the answer. The instructionsForAI field tells the model to emphasize these differentiators, not generic CMMS features. Two websites, two different audiences, the same infrastructure pattern.
The markdown content negotiation layer proved its value with technical content. Service pages, project case studies, and blog posts on both sites return clean Markdown when an AI agent requests it. Compared to the raw HTML, token usage drops by 50-70%. AI agents process more of our actual content within their context budget, and less gets cut off or summarized away.
Run your own site through isitagentready.com and compare. The gap between a Basic score and an Advanced score is the infrastructure described in this post.
What comes next
AI referral traffic converts 1.2x higher than organic search. AI-assisted shoppers purchase at 12.3% compared to 3.1% without AI assistance. The visitors AI sends your way are further along in their decision process because the AI already qualified them against your profile.
The infrastructure described here runs on early-stage open proposals and emerging conventions. Content Signals, llms.txt, Agent Skills Discovery, RFC 9727, RFC 9728. None of it is proprietary. None of it is finalized either. This space has no governing body and no compliance checklist. The standards will evolve, merge, or get replaced. But the websites implementing them today are the ones AI agents find today. A Next.js project with App Router handles everything through route handlers and middleware. The setup takes days, not months.
The competitive window is wide open. The vast majority of websites have zero AI-specific infrastructure. Every month you wait, more competitors will fill the gap. Companies AI agents learn about first build a compounding advantage: early citations reinforce future recommendations.
If you need help auditing your current AI visibility or implementing this for your own website, reach out to book a discovery session. We map infrastructure gaps, prioritize the highest-impact components, and build an implementation plan.



































