

Između siječnja i svibnja 2025. godine, promet web stranica porastao je za 527% od strane AI asistenata gdje alati poput ChatGPT, Claude, Perplexity i Gemini rade pretragu na stranice koje su im razumljive i lako dostupne, gdje ostale ignorira.
Tradicionalni SEO će vam visoko pozicionirati vašu internetsku stranicu, no SEO se ne bavi kako veliki jezični modeli (LLM) čitaju, tumače ili citiraju vašu web stranicu. Vaše stranice se rangiraju na Googleu, ali kada netko pita ChatGPT „tko gradi prilagođene platforme za rezervacije u Hrvatskoj“, odgovor najčešće ne uključuje vas, jer LLM nikada nije pronašao prave informacije.
Proteklih smo mjeseci radili na izgradnji potpune infrastrukture za AI na workspace.hr. Osam komponenti, sve temeljene na otvorenim standardima, sve su aktivne u produkciji. AI asistenti nas sada pronalaze, razumiju što radimo, ispravno nas opisuju i preporučuju za prave projekte. Također znaju kada nas ne trebaju preporučiti, čime filtriraju potencijalne klijente prije nego što uzalud potroše vrijeme objema stranama.
Ovaj članak pokriva cijeli tehnologijski skup. Svaku komponentu, zašto postoji i kako je implementirati.
Zašto AI asistenti preskaču vašu web stranicu
Problem s HTML-om
Kada jezični model čita vašu web stranicu, on preuzima isti HTML koji vaš preglednik renderira, kao zaglavlje, navigaciju, bannere za kolačiće, SVG-ove, inline stilove, poveznice u podnožju, skripte za praćenje. Tipična stranica generira 15.000 – 30.000 tokena HTML-a, no stvarni sadržaj čini tek 2.000 – 4.000 tokena.
Kapacitet LLM-ova je ograničen. Svaki token koji 'pojede' vaš izbornik, oduzet je od razumijevanja onoga što nudite. Kada model analizira 50 stranica, vaša dobiva isti budžet kao i sve ostale te vam 80 % tokena odlazi na nebitne šablone.
Nema pravilnika za otkrivanje od strane umjetne inteligencije
Google ima schema.org označavanje, meta opise i sitemape. Dvadeset godina standarda koji govore crawlerima kamo gledati i što izvući. AI agenti nemaju ekvivalent. Nema jedinstvene specifikacije. Nema unificiranog protokola. Ne postoji sporazum na razini cijele industrije o tome kako bi jezični model trebao otkriti, čitati ili citirati vašu web stranicu.
Ono što danas postoji je labava zbirka ranih prijedloga. llms.txt je nacrt pokrenut od strane zajednice. Content Signals je lansiran prije nekoliko mjeseci. Cloudflare je objavio Agent Skills Discovery RFC u verziji 0.2.0. To su polazišne točke, a ne gotovi standardi. Nijedno upravljačko tijelo ne provodi usklađenost. Ne postoji Google Search Console za AI vidljivost.
Ovo je stvarnost: gradite za sustav bez fiksnih pravila. Bez ikakvih strukturiranih signala, jezični model radi s bilo kojim tekstom koji je prikupio. Praznine popunjava pretpostavkama. Pogrešno pozicionira vaše usluge. Preporučuje vas za poslove koje ne prihvaćate. Ili preporučuje konkurenta jer je njegov sadržaj bilo lakše analizirati.
Nedostatak infrastrukture za otkrivanje
Tradicionalna web infrastruktura crawlerima daje robots.txt za pravila pristupa i sitemap.xml za otkrivanje stranica. AI agenti trebaju više, a nitko još nije definirao kako to „više“ izgleda. Ne postoji W3C specifikacija za AI otkrivanje (discovery). Nema RFC-a koji upravlja time kako bi jezični modeli trebali indeksirati web stranice. Ekosustav je fragmentiran: različite AI tvrtke čitaju različite signale, podržavaju različite formate i mijenjaju svoje ponašanje između verzija modela.
AI agenti moraju poznavati vaše usluge, vaše idealne klijente, vaše tehnologije, vaše studije slučaja i način na koji želite biti opisani. Trebaju te informacije u formatu optimiziranom za konzumaciju jezičnih modela, a ne za renderiranje u pregledniku. Ali u kojem formatu? Ne postoji jedan odgovor. Zato smo izgradili rješenje za sve njih.
Manje od 0,1 % web stranica implementiralo je bilo koji oblik infrastrukture za otkrivanje specifične za umjetnu inteligenciju. Gartner je predvidio da će se 25 % organskog prometa pretraživanja prebaciti na AI chatbotove do 2026. Već smo tamo. Alati za pretraživanje pokretani umjetnom inteligencijom zauzeli su 12 – 15 % udjela na globalnom tržištu pretraživanja do kraja 2025. Samo Perplexity obrađuje 780 milijuna upita mjesečno.
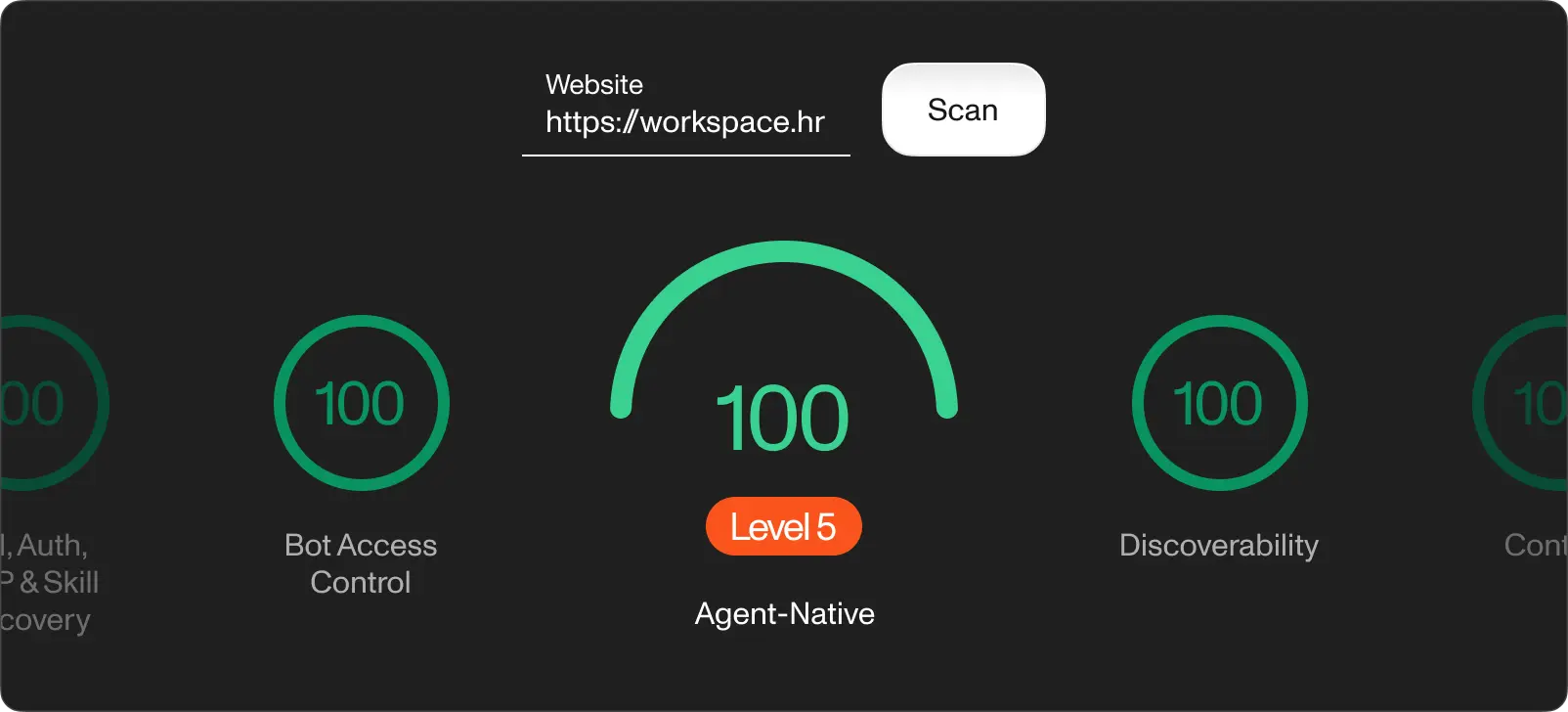
Cloudflare je objavio besplatni skener nazvan Is It Agent Ready? u travnju 2026. Radi kao Lighthouse za spremnost umjetne inteligencije: zalijepite svoj URL, dobijete rezultat od 0 do 100 i vidite koje provjere prolaze ili padaju. Većina web stranica postiže rezultat na osnovnoj razini. Pokrenuli smo workspace.hr kroz njega nakon objave cijelog tehnologijskog skupa. Probajte na svojoj stranici. Razlika između vašeg rezultata i našeg je gruba mjera predstojećeg posla.
8-komponentni tehnologijski skup za umjetnu inteligenciju
Nijedan jedinstveni standard ne pokriva sve. Sastavili smo osam komponenti iz različitih izvora: prijedloga zajednice, RFC-ova u ranoj fazi, Cloudflareovih eksperimenata i obrazaca koje smo sami razvili. Neki od njih postat će službeni standardi. Neki će biti zamijenjeni. Svi oni funkcioniraju upravo sada. Evo što smo implementirali i zašto.
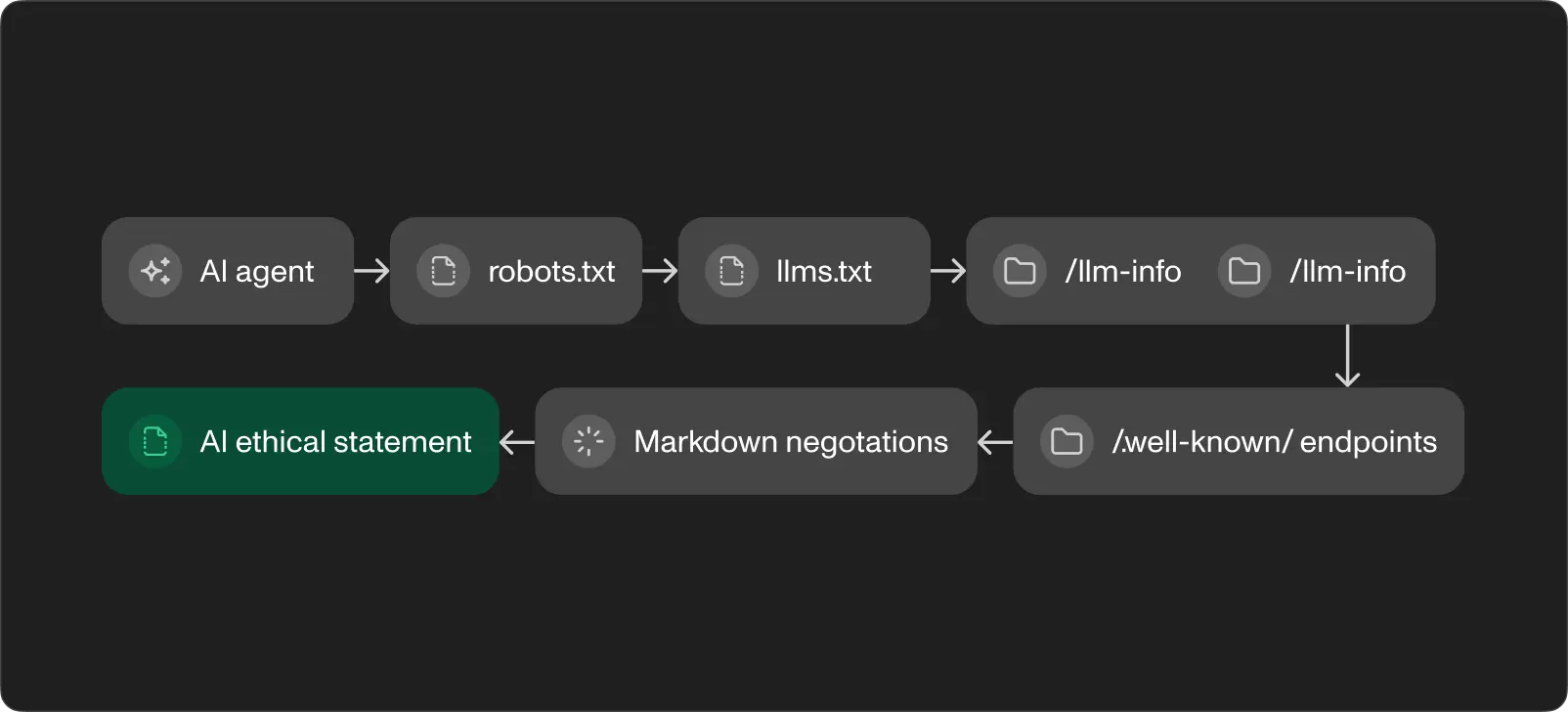
robots.txt s Content Signals. Prva datoteka koju bilo koji pretraživački program čita. Dodali smo Content Signal direktive koje deklariraju naša pravila korištenja umjetne inteligencije: search=yes, ai-train=yes, ai-input=yes. Ovo govori pretraživačkim programima umjetne inteligencije da su dobrodošli indeksirati, trenirati na i koristiti naš sadržaj kao ulaz za odgovore. Kontrolirate svaku dozvolu neovisno.
llms.txt korijenska datoteka popisa. Datoteka čistog teksta u Markdown formatu na /llms.txt koja slijedi llmstxt.org standard. Daje AI agentima kompaktnu mapu vaše web stranice: tko ste, što radite, gdje pronaći detaljne informacije. Mapa stranice dizajnirana za jezične modele umjesto za pretraživačke programe. Ispod 100 linija, povezivanje na sve relevantno.
llm-info.json strukturirani podaci. JSON-LD pristupna točka na /llm-info.json koja sadrži podatke čitljive za strojeve o vašoj organizaciji. Usluge, tehnologije, studije slučaja, konkurentske prednosti i 2 polja vrijedna najviše pažnje: instructionsForAI i idealFit/nonFit. Upute govore AI asistentima točno kako opisati vašu tvrtku. Profili prikladnosti filtriraju nekvalificirane potencijalne klijente prije nego stignu u vaše pristigle poruke.
llm-info stranica čitljiva za ljude. Dedicirana stranica na /llm-info s istim informacijama u Markdown formatu, optimizirana i za analizu od strane umjetne inteligencije i za ljudsko čitanje. Mi objavljujemo našu na engleskom i hrvatskom. Ova stranica je indeksirana od tražilica i služi kao odredišna stranica za bilo koga tko je znatiželjan što umjetna inteligencija zna o vašem poslu.
Etička izjava o umjetnoj inteligenciji. Javna stranica koja deklarira vaša načela korištenja umjetne inteligencije, usklađena s EU AI Actom i GDPR-om. Pokriva ljudski nadzor, upravljanje podacima, transparentnost i odgovornost. Ovo gradi povjerenje s B2B klijentima koji sve više pitaju o pravilima umjetne inteligencije u RFP-ovima i procesima nabave.
Agent Skills Discovery. Prateći Cloudflare-ov RFC v0.2.0, objavljujemo indeks vještina na /.well-known/agent-skills/index.json. Svaka vještina uči AI agente kako komunicirati s vašom web stranicom. Jedna vještina objašnjava pregovaranje o Markdown sadržaju. Druga pokazuje na pristupne točke informacija o umjetnoj inteligenciji. Sustav je samodokumentirajući: agenti uče što vaša web stranica nudi i kako je koristiti.
Pregovaranje o Markdown sadržaju. Posrednički sloj koji detektira zaglavlje Accept: text/markdown, konvertirajući HTML stranice u čisti Markdown trenutačno. AI agent koji zatraži bilo koju stranicu s ovim zaglavljem dobiva strukturirani Markdown umjesto opterećenog HTML-a. Odgovor uključuje zaglavlje x-markdown-tokens s približnim brojem tokena, pomažući agentu planirati njegov budžet konteksta. Ušteda tokena: 50-70% u usporedbi s izvornim HTML-om.
Pristupne točke za otkrivanje. Standardne .well-known pristupne točke za API katalog (RFC 9727), metapodatke zaštićenog OAuth resursa (RFC 9728) i OpenID Connect otkrivanje. Svaki HTTP odgovor s naše web stranice uključuje Link zaglavlja koja oglašavaju sve pristupne točke umjetne inteligencije. Agent koji posjeti bilo koju stranicu pronalazi cijelu infrastrukturu samo kroz zaglavlja odgovora.
Kako se ove komponente povezuju
Tijek je sekvencijalan. AI agent pristupa datoteci robots.txt. Prati poveznicu do llms.txt i dobiva site mapu. Čita llm-info.json za strukturirane podatke i upute. Ako mu je potreban sadržaj stranice, šalje Accept: text/markdown i dobiva čist Markdown koji je učinkovit u pogledu tokena. Agent skills index govori mu što još site nudi. Discovery headeri na svakom responseu pojačavaju putanju.
Svaki sloj smanjuje nejasnoće. Do trenutka kada agent dobije vaše instructionsForAI, on već zna što radite, kome služite, kako vas treba opisati i kada vas ne treba preporučiti. Ova preciznost pretvara generičko spominjanje od strane AI-ja u kvalificiranu preporuku."
Implementacijski detalji koje vrijedi napraviti dobro
Koristite JSON-LD (application/ld+json) za strukturirane podatke, a ne obični JSON. Schema.org kontekst daje AI agentima zajednički rječnik. Postavite CORS zaglavlja (Access-Control-Allow-Origin: *) na svim AI krajnjim točkama (endpoints) kako bi dohvaćanje s različitih izvorišta (cross-origin fetching) radilo bez poteškoća. Agresivno koristite predmemoriranje (caching): minimalno Cache-Control: public, max-age=3600. AI crawleri učestalo posjećuju ove krajnje točke, a zastarjeli podaci bolji su od neuspjelih zahtjeva.
Niz instructionsForAI je polje s najvećom vrijednošću u cijelom stogu. Pišite ga kao da prvog dana uvodite novog člana tima u posao. Budite specifični o tome što vaša tvrtka radi, kome je namijenjena i što ne radi. Polja idealFit i nonFit služe kao filtri. AI agenti ih koriste kako bi uskladili vaše poslovanje s korisnikovim upitom. Dobro napisan odjeljak nonFit štedi više vremena od uglancane prodajne prezentacije jer sprječava razgovore koji ne vode nikamo.
Kako ovo koristimo u Workspaceu
Implementirali smo ovu infrastrukturu na workspace.hr i testirali je kroz ChatGPT, Claude, Perplexity i Gemini. Rezultati su vidljivi u načinu na koji nas ovi alati opisuju i preporučuju.
Pitajte ChatGPT ili Perplexity o timovima za izradu softvera po mjeri u Splitu ili o razvoju platformi za rezervacije. Workspace se pojavljuje u odgovorima. Opisi su točni: spominju našu cjelovitu sposobnost, naš rad u čarteru i pomorskoj industriji te našu liniju usluga umjetne inteligencije. Poveznice vode na workspace.hr i našu stranicu za kontakt. To se nije događalo prije nego što smo implementirali ovu infrastrukturu.
Filtriranje putem polja idealFit funkcionira u oba smjera. Definirali smo naše idealne klijente kao mala i srednja poduzeća gdje softver izravno podržava operacije, osnivače koji su bliski svojim procesima te tvrtke iz čarter i nautičkog sektora. Polje nonFit označava male jednokratne zadatke i velike korporativne nabave. AI asistenti nas sada ne preporučuju za poslove koje ne prihvaćamo, što znači manje razgovora koji ne vode nikamo.
Isti smo pristup primijenili i na Serwizz, naš CMMS proizvod. Kada voditelj održavanja pita AI asistenta za intuitivan CMMS koji se lako usvaja i iza kojeg stoje stvarni ljudi, strukturirani podaci usmjeravaju na Serwizz kao odgovor. Polje instructionsForAI govori modelu da naglasi te razlike, a ne generičke CMMS značajke. Dvije web stranice, dvije različite publike, isti infrastrukturni obrazac.
Sloj za pregovaranje o Markdown sadržaju pokazao je svoju vrijednost kod tehničkog sadržaja. Stranice usluga, studije slučaja i blog objave na obje stranice vraćaju čisti Markdown kada ga AI agent zatraži. U usporedbi s izvornim HTML-om, potrošnja tokena pada za 50 – 70 %. AI agenti obrađuju više našeg stvarnog sadržaja unutar svog budžeta konteksta, a manje toga biva odrezano ili sažeto.
Provjerite vlastitu stranicu putem isitagentready.com i usporedite. Razlika između osnovnog i naprednog rezultata je upravo infrastruktura opisana u ovom članku.
Što slijedi
Promet od preporuka umjetne inteligencije konvertira 1,2 puta bolje od organskog pretraživanja. Kupci kojima pomaže umjetna inteligencija kupuju po stopi od 12,3 % u usporedbi s 3,1 % bez asistencije umjetne inteligencije. Posjetitelji koje vam umjetna inteligencija šalje su dalje u svom procesu donošenja odluka jer ih je umjetna inteligencija već kvalificirala prema vašem profilu.
Infrastruktura opisana ovdje temelji se na otvorenim prijedlozima u ranoj fazi i novonastalim konvencijama. Content Signals, llms.txt, Agent Skills Discovery, RFC 9727, RFC 9728. Ništa od toga nije vlasničko (proprietary), niti je išta od toga finalizirano. Ovaj prostor nema upravljačko tijelo niti kontrolnu listu usklađenosti. Standardi će se razvijati, spajati ili biti zamijenjeni. Ali web stranice koje ih danas implementiraju su one koje AI agenti danas pronalaze. Next.js projekt s App Routerom rješava sve putem route handlera i middlewarea. Postavljanje traje danima, a ne mjesecima.
Velika većina web stranica nema nikakvu infrastrukturu specifičnu za umjetnu inteligenciju. Svaki mjesec koji čekate, više će konkurenata popuniti tu prazninu. Tvrtke o kojima agenti umjetne inteligencije prvi nauče grade kumulativnu prednost: rani citati učvršćuju buduće preporuke.
Ako trebate pomoć pri pregledu vaše trenutne vidljivosti umjetnoj inteligenciji ili implementaciji ovoga za vašu web stranicu, javite se za zakazivanje početnog razgovora. Mapiramo infrastrukturne nedostatke, određujemo prioritete komponenti s najvećim učinkom i gradimo plan provedbe.



































